How Navigation Agents Follow Spatial Intelligence Instructions
NavSpace: We introduce the first spatial intelligence benchmark for instruction-based navigation: NavSpace.
Evaluation: we comprehensively evaluate 22 navigation agents in total, containing models from open-source MLLM, proprietary MLLM, lightweight navigation models to navigation large models.
Discussions: Based on the evaluation results, we conducted a detailed analysis of the limitations of existing methods and distilled four key insights.
Baseline Model: SNav: We propose SNav, a spatially intelligent navigation model, that surpasses existing models and establishes a strong baseline for NavSpace and real robot tests.
NavSpace: How Navigation Agents Follow Spatial Intelligence Instructions
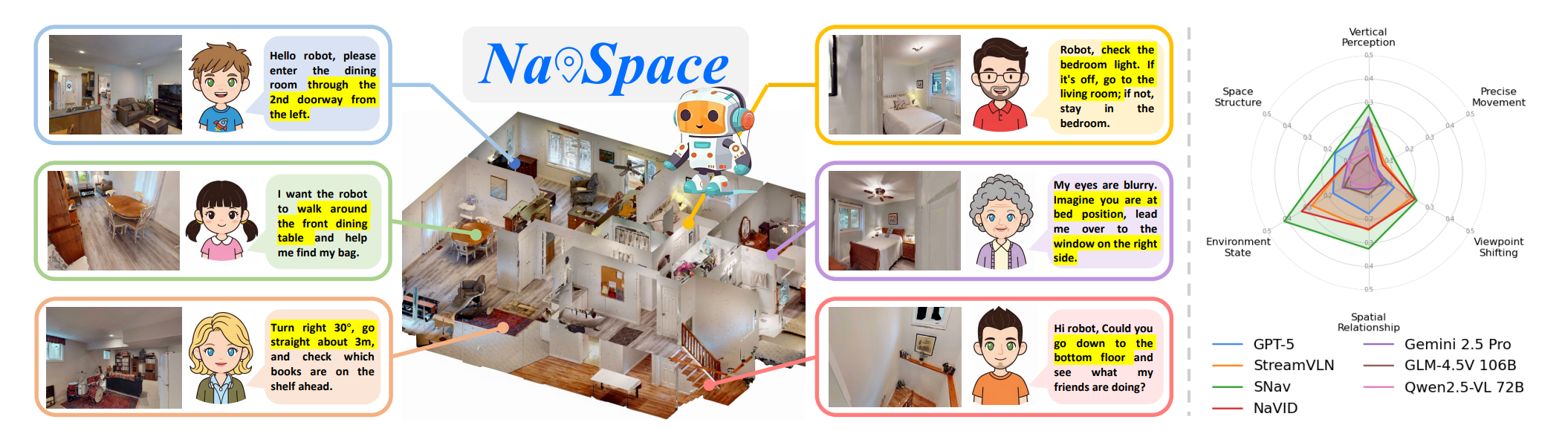
Figure 1: (Left) NavSpace tasks. (Right) Evaluation results compare various models with baseline SNav.
NavSpace Introduction
Benchmark Overview:
We introduce the NavSpace benchmark, which
contains six task categories and 1,228 trajectory-instruction
pairs designed to probe the spatial intelligence of navigation
agents. On this benchmark, we comprehensively evaluate 22
navigation agents, including state-of-the-art navigation models
and multimodal large language models. The evaluation results
lift the veil on spatial intelligence in embodied navigation.
Furthermore, we propose SNav, a new spatially intelligent
navigation model. SNav outperforms existing navigation agents
on NavSpace and real robot tests, establishing a strong baseline
for future work.
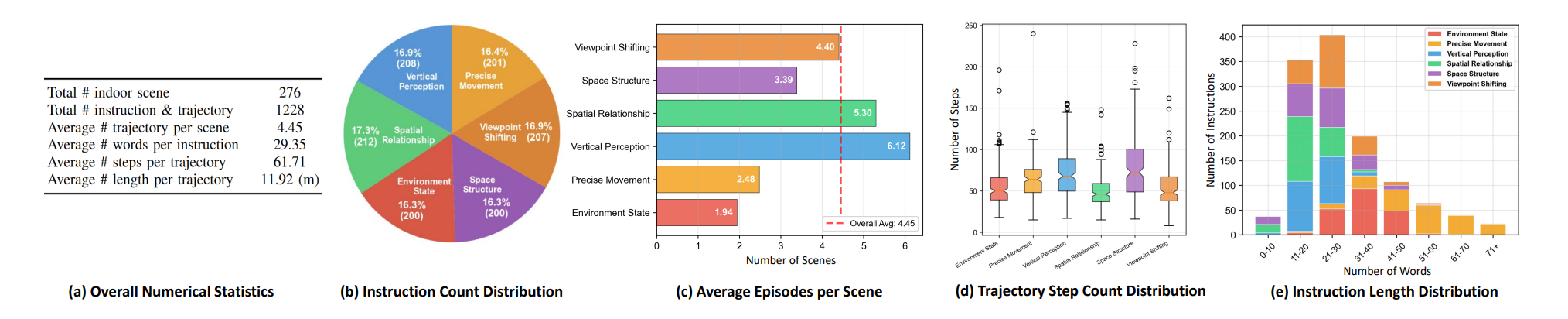
Figure 2: Instruction Categories in NavSpace.
These six categories were determined based on the questionnaire survey results. Every navigation trajectory and instruction was collected manually from HM3D scene datasets through our designed platform.
Figure 3: Visualization of NavSpace Statistics.
NavSpace Construction:
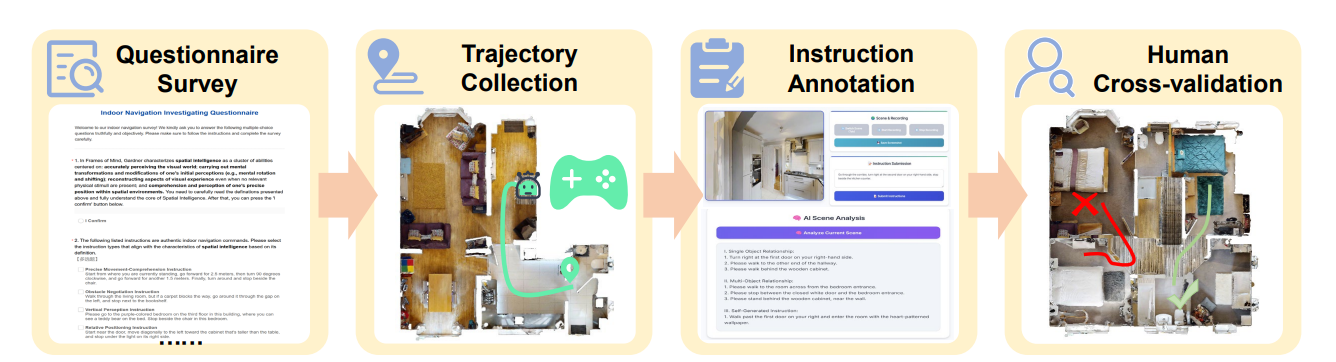
We designed a two-part survey to identify navigation instructions indicative of spatial intelligence. Participants first reviewed a definition of spatial intelligence and confirmed comprehension, then evaluated 17 candidate instruction types, selecting up to six. From 512 responses, 457 valid ones were retained, yielding six key categories: Vertical Perception, Precise Movement, Viewpoint Shifting, Spatial Relationship, Environment State, and Space Structure. To collect trajectories, we built a Habitat 3.0-based platform with HM3D scenes, integrating a front-end annotation webpage and simulator-linked backend. Annotators teleoperated agents in first-person view, recording RGB frames, actions, and coordinates. GPT-5 then analyzed trajectories, combining navigation data with sampled visual observations to generate candidate instructions, which annotators refined and finalized. For quality assurance, cross-validation required each instruction to be executed by a different annotator; unsuccessful cases were discarded and re-annotated. This pipeline ensured collected data were diverse in spatial reasoning and reliable for downstream evaluation.
Figure 4: Construction pipeline of NavSpace. (1) Questionnaire Survey: identify navigation instruction types that best reflect spatial intelligence. (2) Trajectory Collection: teleoperate agents in simulation to record trajectories. (3) Instruction Annotation: generate instructions with large-model-assisted analysis. (4) Human Cross-Validation: review and validate instructions for correctness and executability.
Evaluation on NavSpace
Evaluation Environment and Metrics:
NavSpace takes Habitat 3.0 as the simulator to conduct the evaluation. Evaluation scenes are selected from the HM3D datasets. At each step, the agent
can only select one action. Following previous instruction
navigation benchmarks, we employ the following widely used evaluation metrics: Navigation Error (NE), Oracle Success Rate (OS), Success Rate (SR).
We conduct a comprehensive evaluation of existing multimodal large models and navigation models. These models can be categorized into the following five types:
Chance Level Baselines
Open-source MLLMs
Proprietary MLLMs
Lightweight Navigation Models
Navigation Large Models
Performances on NavSpace:
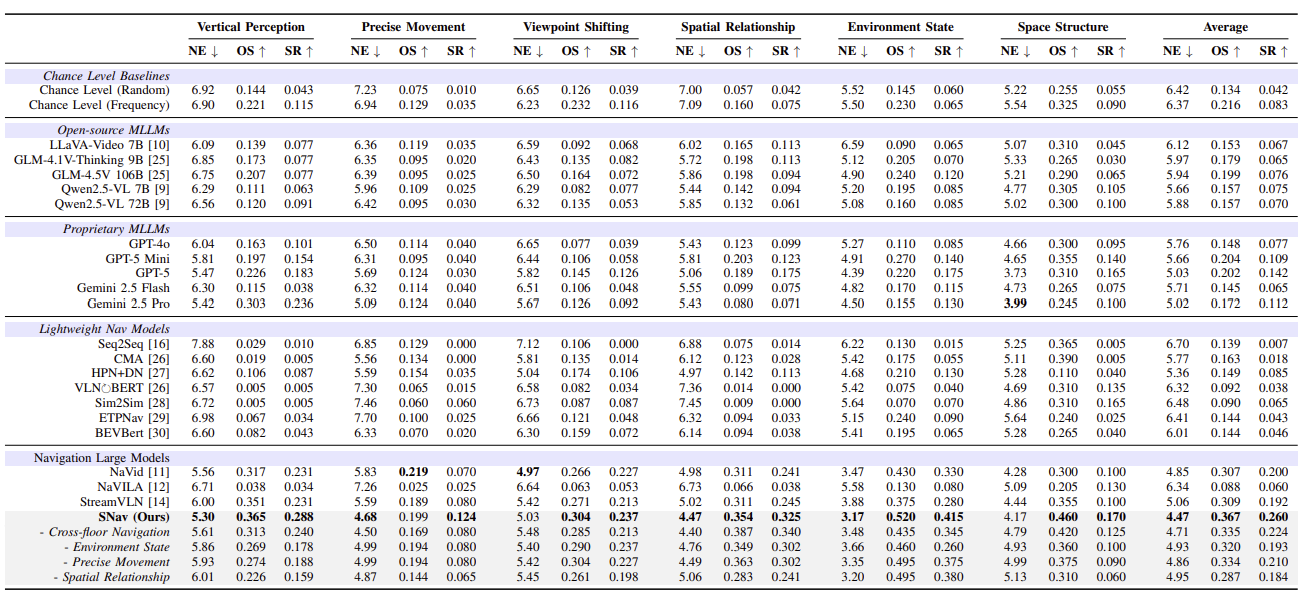
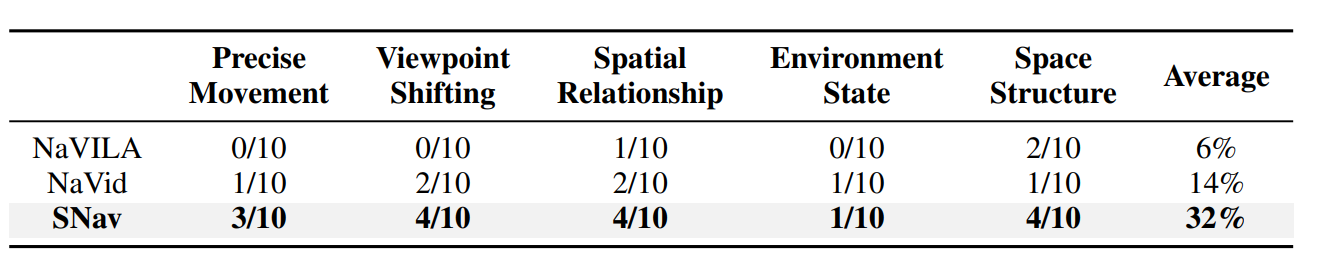
NavSpace poses a major challenge for current models. Open-source MLLMs achieve less than 10% success, near chance level, while proprietary MLLMs perform slightly better, with GPT-5 leading but still under 20%. This indicates that existing MLLMs are far from reliable navigation agents for spatial intelligence tasks. Lightweight navigation models such as BEVBert and ETPNav also fail on NavSpace, whereas larger navigation models like NaVid and StreamVLN outperform GPT-5 and show preliminary spatial reasoning ability. Our proposed model, SNav, surpasses both state-of-the-art navigation models and advanced MLLMs, establishing a strong new baseline. Ablation results further demonstrate that its instruction-generation pipeline is key to enhancing spatial intelligence performance.
Table 1: Quantative performances on NavSpace. Bold color indicates the best result among all models
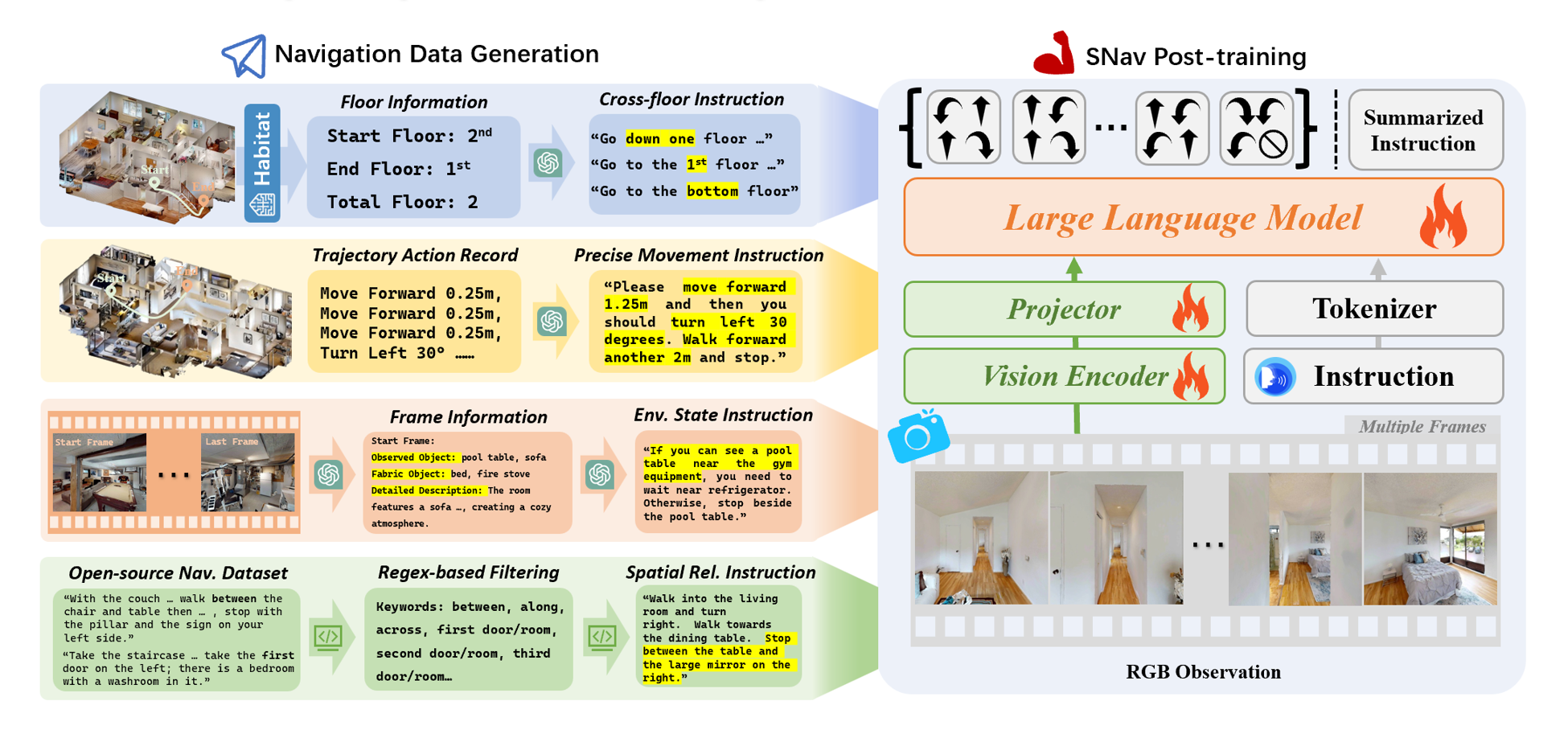
Our SoTA Model——SNav:
The architecture of the SNav incorporates three fundamental
components: the Vision Encoder v(·), the Projector p(·),
and the Large Language Model (LLM) f(·). We follow the previous work to conduct navigation
finetuning through co-training with three tasks. These
tasks include Navigation Action Prediction, Trajectory-based
Instruction Generation, and General Multimodal Data Recall.
After this, we obtain the vanilla SNav model.
Spatial Intelligence Enhancement:
Cross-floor Navigation: We identify R2R trajectories likely to cross floors by thresholding height differences between start and end. For each candidate, the agent follows a shortest-path planner in Habitat while recording RGB frames. A trajectory is labeled floor-crossing if GPT-5 detects stairs in ≥3 frames. Using methods from HOV-SG, we assign floor labels to start/end points and combine them with Habitat's floor count for vertical-space annotations. GPT-5 then restyles raw instructions (e.g., “Walk up the stairs ...”) into floor-specific ones (e.g., “Walk up to the third floor ...”).
Precise Movement: We sample start-goal pairs in MP3D scenes and compute shortest paths in Habitat. After filtering, trajectories of target length (20-60 steps) are retained, with discrete actions recorded (turn ±30°, move forward 0.25m, stop). Consecutive actions of the same type are merged into concise descriptions (e.g., “move forward 3 m, turn right 60°, move forward 2 m”). GPT-5 paraphrases these into natural-language instructions.
Environment State Inference: We extract start-end point pairs with navigation instructions from the R2R dataset and generate trajectories using a shortest-path planner, saving RGB frames along each path. GPT-5 is then queried with the first and last frames to infer three elements: observable objects, unobservable objects, and scene descriptions. After observing the structure of this category, we design five template categories that integrate multimodal observations with original instructions. Two representative patterns are: (1) Original_instruction; if [visible_object in last frame] then stop at [last-frame location], otherwise go to [scene description from first frame], and (2) If [fabricated_object in first frame] then stop, otherwise follow Original_instruction and stop at [last-frame location]. GPT-5 rewrites instructions according to these templates, producing high-quality training data for environment state inference.
Spatial Relationship: We filter R2R instructions with regular expressions for ordinal phrases (“first room/door”, “second room/door”, etc.) and detect multi-object relations using keywords like “between”, “along”, and “across”.
Figure 4: Spatial Intelligence Enhancement.
Real World Tests:
In the real-world test, we test our model SNav across three different environments:
office, campus, and outdoor environments. The test covers
five categories of spatially intelligent navigation instructions
(excluding vertical perception). Our experimental platform is
the AgiBot Lingxi D1 quadruped, which is equipped with
a monocular RGB camera and motion-control APIs.
Figure 5: Qualitative results from the real-world deployment of SNav. The evaluated instructions cover five categories
proposed in NavSpace. The test environment includes the office, the campus building, and the outdoor area.
TABLE 3: Quantitative Results of Real-World Experiments.
NavSpace Leaderboard
To include your model in the leaderboard, please email NavSpace@163.com with evaluation logs and setups.
Model
LLM Params
Frames
Date
Avg Success Rate(%).
Vertical Perception(SR)
Precise Movement(SR)
Viewpoint Shifting(SR)
Spatial Relationship(SR)
Environment State(SR)
Space Structure(SR)
Chance Level Baselines
Chance-level (Random)
-
-
2025-09-25
4.2
4.3
1.0
3.9
4.2
6.0
5.5
-
-
Chance-level (Frequency)
-
-
2024-11-15
8.3
11.5
3.5
11.6
7.5
6.5
9.0
-
-
Open-source MLLMs
LLaVA-Video
7B
64
2025-09-26
6.7
7.7
3.5
6.8
11.3
6.5
4.5
-
-
GLM-4.1V-Thinking
9B
64
2025-09-26
6.5
7.7
2.0
8.2
11.3
7.0
3.0
-
-
GLM-4.5V
106B
64
2025-09-26
7.6
7.7
2.5
7.2
9.4
12.0
6.5
-
-
Qwen2.5-VL
7B
64
2025-09-26
7.5
6.3
2.5
7.7
9.4
8.5
10.5
-
-
Qwen2.5-VL
72B
64
2025-09-26
7.0
9.1
3.0
5.3
6.1
8.5
10.0
-
-
Proprietary MLLMs
GPT-4o
-
32
2025-09-26
7.7
10.1
4.0
3.9
9.9
8.5
9.5
-
-
GPT-5 Mini
-
32
2025-09-26
10.9
15.4
4.0
5.8
12.3
14.0
14.0
-
-
GPT-5
-
32
2025-09-26
14.2
18.3
3.0
12.6
17.5
17.5
16.5
-
-
Gemini 2.5 Flash
-
32
2025-09-26
6.5
3.8
4.0
4.8
7.5
11.5
7.5
-
-
Gemini 2.5 Pro
-
32
2025-09-26
11.2
23.6
4.0
9.2
7.1
13.0
10.0
-
-
Lightweight Nav Models
Seq2Seq
-
16
2025-09-26
0.7
1.0
0.0
0.0
1.4
1.5
0.5
-
-
CMA
-
32
2025-09-26
1.8
0.5
0.0
1.4
2.8
5.5
0.5
-
-
HPN+DN
-
32
2025-09-26
8.5
8.7
3.5
10.6
11.3
13.0
4.0
-
-
VLN↺BERT
-
32
2025-09-26
3.8
0.5
1.5
3.4
0.0
4.0
13.5
-
-
Sim2Sim
-
32
2025-09-26
6.5
0.5
6.0
8.7
0.0
7.0
16.5
-
-
ETPNav
-
32
2025-09-26
4.3
3.4
2.5
4.8
3.3
9.0
2.5
-
-
BEVBert
-
32
2025-09-26
4.6
4.3
2.0
7.2
3.8
6.5
4.0
-
-
Navigation Large Models
NaVid
7B
32
2025-09-26
20.0
23.1
7.0
22.7
24.1
33.0
10.0
-
-
NaVILA
7B
32
2025-09-26
6.0
3.4
2.5
5.3
3.8
8.0
13.0
-
-
StreamVLN
7B
32
2025-09-26
19.2
23.1
8.0
21.3
24.5
28.0
10.0
-
-
SNav(Ours)
7B
32
2025-09-26
26.0
28.8
12.4
23.7
32.5
41.5
17.0
-
-
BibTeX
@misc{yang2025navspacenavigationagentsfollow,
title={NavSpace: How Navigation Agents Follow Spatial Intelligence Instructions},
author={Haolin Yang and Yuxing Long and Zhuoyuan Yu and Zihan Yang and Minghan Wang and Jiapeng Xu and Yihan Wang and Ziyan Yu and Wenzhe Cai and Lei Kang and Hao Dong},
year={2025},
eprint={2510.08173},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2510.08173},
}